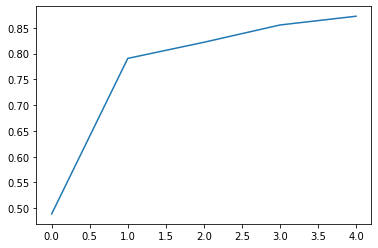
Model: "model_4"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_6 (InputLayer) [(None, 96, 128, 3) 0 []
]
conv2d_26 (Conv2D) (None, 96, 128, 32) 896 ['input_6[0][0]']
conv2d_27 (Conv2D) (None, 96, 128, 32) 9248 ['conv2d_26[0][0]']
max_pooling2d_6 (MaxPooling2D) (None, 48, 64, 32) 0 ['conv2d_27[0][0]']
conv2d_28 (Conv2D) (None, 48, 64, 64) 18496 ['max_pooling2d_6[0][0]']
conv2d_29 (Conv2D) (None, 48, 64, 64) 36928 ['conv2d_28[0][0]']
max_pooling2d_7 (MaxPooling2D) (None, 24, 32, 64) 0 ['conv2d_29[0][0]']
conv2d_30 (Conv2D) (None, 24, 32, 128) 73856 ['max_pooling2d_7[0][0]']
conv2d_31 (Conv2D) (None, 24, 32, 128) 147584 ['conv2d_30[0][0]']
max_pooling2d_8 (MaxPooling2D) (None, 12, 16, 128) 0 ['conv2d_31[0][0]']
conv2d_32 (Conv2D) (None, 12, 16, 256) 295168 ['max_pooling2d_8[0][0]']
conv2d_33 (Conv2D) (None, 12, 16, 256) 590080 ['conv2d_32[0][0]']
dropout_3 (Dropout) (None, 12, 16, 256) 0 ['conv2d_33[0][0]']
max_pooling2d_9 (MaxPooling2D) (None, 6, 8, 256) 0 ['dropout_3[0][0]']
conv2d_34 (Conv2D) (None, 6, 8, 512) 1180160 ['max_pooling2d_9[0][0]']
conv2d_35 (Conv2D) (None, 6, 8, 512) 2359808 ['conv2d_34[0][0]']
dropout_4 (Dropout) (None, 6, 8, 512) 0 ['conv2d_35[0][0]']
conv2d_transpose_5 (Conv2DTran (None, 12, 16, 256) 1179904 ['dropout_4[0][0]']
spose)
concatenate_5 (Concatenate) (None, 12, 16, 512) 0 ['conv2d_transpose_5[0][0]',
'dropout_3[0][0]']
conv2d_36 (Conv2D) (None, 12, 16, 256) 1179904 ['concatenate_5[0][0]']
conv2d_37 (Conv2D) (None, 12, 16, 256) 590080 ['conv2d_36[0][0]']
conv2d_transpose_6 (Conv2DTran (None, 24, 32, 128) 295040 ['conv2d_37[0][0]']
spose)
concatenate_6 (Concatenate) (None, 24, 32, 256) 0 ['conv2d_transpose_6[0][0]',
'conv2d_31[0][0]']
conv2d_38 (Conv2D) (None, 24, 32, 128) 295040 ['concatenate_6[0][0]']
conv2d_39 (Conv2D) (None, 24, 32, 128) 147584 ['conv2d_38[0][0]']
conv2d_transpose_7 (Conv2DTran (None, 48, 64, 64) 73792 ['conv2d_39[0][0]']
spose)
concatenate_7 (Concatenate) (None, 48, 64, 128) 0 ['conv2d_transpose_7[0][0]',
'conv2d_29[0][0]']
conv2d_40 (Conv2D) (None, 48, 64, 64) 73792 ['concatenate_7[0][0]']
conv2d_41 (Conv2D) (None, 48, 64, 64) 36928 ['conv2d_40[0][0]']
conv2d_transpose_8 (Conv2DTran (None, 96, 128, 32) 18464 ['conv2d_41[0][0]']
spose)
concatenate_8 (Concatenate) (None, 96, 128, 64) 0 ['conv2d_transpose_8[0][0]',
'conv2d_27[0][0]']
conv2d_42 (Conv2D) (None, 96, 128, 32) 18464 ['concatenate_8[0][0]']
conv2d_43 (Conv2D) (None, 96, 128, 32) 9248 ['conv2d_42[0][0]']
conv2d_44 (Conv2D) (None, 96, 128, 32) 9248 ['conv2d_43[0][0]']
conv2d_45 (Conv2D) (None, 96, 128, 23) 759 ['conv2d_44[0][0]']
==================================================================================================
Total params: 8,640,471
Trainable params: 8,640,471
Non-trainable params: 0
__________________________________________________________________________________________________