It’s time to build your first neural network, which will have one hidden layer. Notice a big difference between this model and the one implemented previously using logistic regression.
In this notebook we will be able to:
Implement a 2-class classification neural network with a single hidden layer
Use units with a non-linear activation function, such as tanh
Compute the cross entropy loss
Implement forward and backward propagation
Packages
First import all the packages that you will need during this assignment.
numpy is the fundamental package for scientific computing with Python.
sklearn provides simple and efficient tools for data mining and data analysis.
matplotlib is a library for plotting graphs in Python.
testCases provides some test examples to assess the correctness of your functions
planar_utils provide various useful functions used in this assignment
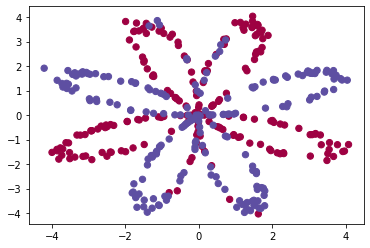
Visualize the dataset using matplotlib. The data looks like a “flower” with some red (label y=0) and some blue (y=1) points. Your goal is to build a model to fit this data. In other words, we want the classifier to define regions as either red or blue.
Code
# Visualize the data:plt.scatter(X[0, :], X[1, :], c=None, s=40, cmap=plt.cm.Spectral);
You have: - a numpy-array (matrix) X that contains your features (x1, x2) - a numpy-array (vector) Y that contains your labels (red:0, blue:1).
First, get a better sense of what your data is like.
How many training examples do you have? In addition, what is the shape of the variables X and Y?
Code
shape_X = X.shapeshape_Y = Y.shapem = (X.size)/shape_X[0] print ('The shape of X is: '+str(shape_X))print ('The shape of Y is: '+str(shape_Y))print ('I have m = %d training examples!'% (m))
The shape of X is: (2, 400)
The shape of Y is: (1, 400)
I have m = 400 training examples!
Simple Logistic Regression
Before building a full neural network, let’s check how logistic regression performs on this problem. You can use sklearn’s built-in functions for this. Run the code below to train a logistic regression classifier on the dataset.
Code
# Train the logistic regression classifierclf = sklearn.linear_model.LogisticRegressionCV();clf.fit(X.T, Y.T);
Code
def plot_decision_boundary(model, X, y):# Set min and max values and give it some padding x_min, x_max = X[0, :].min() -1, X[0, :].max() +1 y_min, y_max = X[1, :].min() -1, X[1, :].max() +1 h =0.01# Generate a grid of points with distance h between them xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))# Predict the function value for the whole grid Z = model(np.c_[xx.ravel(), yy.ravel()]) Z = Z.reshape(xx.shape)# Plot the contour and training examples plt.contourf(xx, yy, Z, cmap=plt.cm.Spectral) plt.ylabel('x2') plt.xlabel('x1') plt.scatter(X[0, :], X[1, :], c=y, cmap=plt.cm.Spectral)
You can now plot the decision boundary of these models! Run the code below.
Code
# Plot the decision boundary for logistic regressionplot_decision_boundary(lambda x: clf.predict(x), X, Y)plt.title("Logistic Regression")# Print accuracyLR_predictions = clf.predict(X.T)print ('Accuracy of logistic regression: %d '%float((np.dot(Y,LR_predictions) + np.dot(1-Y,1-LR_predictions))/float(Y.size)*100) +'% '+"(percentage of correctly labelled datapoints)")
Accuracy of logistic regression: 47 % (percentage of correctly labelled datapoints)
Interpretation: The dataset is not linearly separable, so logistic regression doesn’t perform well. Hopefully a neural network will do better. Let’s try this now!
Neural Network model
Logistic regression didn’t work well on the flower dataset. Next, you’re going to train a Neural Network with a single hidden layer and see how that handles the same problem.
Mathematical Model:
For one example \(x^{(i)}\): \[z^{[1] (i)} = W^{[1]} x^{(i)} + b^{[1]}\tag{1}\]\[a^{[1] (i)} = \tanh(z^{[1] (i)})\tag{2}\]\[z^{[2] (i)} = W^{[2]} a^{[1] (i)} + b^{[2]}\tag{3}\]\[\hat{y}^{(i)} = a^{[2] (i)} = \sigma(z^{ [2] (i)})\tag{4}\]
Given the predictions on all the examples, you can also compute the cost \(J\) as follows: \[J = - \frac{1}{m} \sum\limits_{i = 0}^{m} \large\left(\small y^{(i)}\log\left(a^{[2] (i)}\right) + (1-y^{(i)})\log\left(1- a^{[2] (i)}\right) \large \right) \small \tag{6}\]
Reminder: The general methodology to build a Neural Network is to: 1. Define the neural network structure ( # of input units, # of hidden units, etc). 2. Initialize the model’s parameters 3. Loop: - Implement forward propagation - Compute loss - Implement backward propagation to get the gradients - Update parameters (gradient descent)
In practice, you’ll often build helper functions to compute steps 1-3, then merge them into one function called nn_model(). Once you’ve built nn_model() and learned the right parameters, you can make predictions on new data.
Defining the neural network structure
layer_sizes
Define three variables: - n_x: the size of the input layer - n_h: the size of the hidden layer - n_y: the size of the output layer
Use shapes of X and Y to find n_x and n_y. Also, hard code the hidden layer size to be 4.
Code
def layer_sizes(X, Y):""" Arguments: X -- input dataset of shape (input size, number of examples) Y -- labels of shape (output size, number of examples) Returns: n_x -- the size of the input layer n_h -- the size of the hidden layer n_y -- the size of the output layer """ n_x = X.shape[0] n_h =4 n_y = Y.shape[0]return (n_x, n_h, n_y)
Code
t_X, t_Y = layer_sizes_test_case()(n_x, n_h, n_y) = layer_sizes(t_X, t_Y)print("The size of the input layer is: n_x = "+str(n_x))print("The size of the hidden layer is: n_h = "+str(n_h))print("The size of the output layer is: n_y = "+str(n_y))layer_sizes_test(layer_sizes)
The size of the input layer is: n_x = 5
The size of the hidden layer is: n_h = 4
The size of the output layer is: n_y = 2
All tests passed!
Initialize the model’s parameters
Implement the function initialize_parameters().
Instructions: - Make sure your parameters’ sizes are right. Refer to the neural network figure above if needed. - You will initialize the weights matrices with random values. - Use: np.random.randn(a,b) * 0.01 to randomly initialize a matrix of shape (a,b). - You will initialize the bias vectors as zeros. - Use: np.zeros((a,b)) to initialize a matrix of shape (a,b) with zeros.
Code
def initialize_parameters(n_x, n_h, n_y):""" Argument: n_x -- size of the input layer n_h -- size of the hidden layer n_y -- size of the output layer Returns: params -- python dictionary containing your parameters: W1 -- weight matrix of shape (n_h, n_x) b1 -- bias vector of shape (n_h, 1) W2 -- weight matrix of shape (n_y, n_h) b2 -- bias vector of shape (n_y, 1) """ W1 = np.random.randn(n_h, n_x) *0.01 b1 = np.zeros((n_h, 1)) W2 = np.random.randn(n_y, n_h) *0.01 b2 = np.zeros((n_y, 1)) parameters = {"W1": W1,"b1": b1,"W2": W2,"b2": b2}return parameters
Check the mathematical representation of your classifier in the figure above.
Use the function sigmoid(). It’s built into (imported) this notebook.
Use the function np.tanh(). It’s part of the numpy library.
Implement using these steps:
Retrieve each parameter from the dictionary “parameters” (which is the output of initialize_parameters() by using parameters[".."].
Implement Forward Propagation. Compute \(Z^{[1]}, A^{[1]}, Z^{[2]}\) and \(A^{[2]}\) (the vector of all your predictions on all the examples in the training set).
Values needed in the backpropagation are stored in “cache”. The cache will be given as an input to the backpropagation function.
Code
def forward_propagation(X, parameters):""" Argument: X -- input data of size (n_x, m) parameters -- python dictionary containing your parameters (output of initialization function) Returns: A2 -- The sigmoid output of the second activation cache -- a dictionary containing "Z1", "A1", "Z2" and "A2" """ W1 = parameters["W1"] b1 = parameters["b1"] W2 = parameters["W2"] b2 = parameters["b2"] Z1 = np.dot(W1,X) + b1 A1 = np.tanh(Z1) Z2 = np.dot(W2,A1) + b2 A2 = sigmoid(Z2)assert(A2.shape == (1, X.shape[1])) cache = {"Z1": Z1,"A1": A1,"Z2": Z2,"A2": A2}return A2, cache
A2 = [[0.21292656 0.21274673 0.21295976]]
All tests passed!
Compute the Cost
Now that you’ve computed \(A^{[2]}\) (in the Python variable “A2”), which contains \(a^{[2](i)}\) for all examples, you can compute the cost function as follows:
Implement compute_cost() to compute the value of the cost \(J\).
Instructions: - There are many ways to implement the cross-entropy loss. This is one way to implement one part of the equation without for loops: \(- \sum\limits_{i=1}^{m} y^{(i)}\log(a^{[2](i)})\):
Use that to build the whole expression of the cost function.
Notes:
You can use either np.multiply() and then np.sum() or directly np.dot()).
If you use np.multiply followed by np.sum the end result will be a type float, whereas if you use np.dot, the result will be a 2D numpy array.
You can use np.squeeze() to remove redundant dimensions (in the case of single float, this will be reduced to a zero-dimension array).
You can also cast the array as a type float using float().
Code
def compute_cost(A2, Y):""" Computes the cross-entropy cost given in equation (13) Arguments: A2 -- The sigmoid output of the second activation, of shape (1, number of examples) Y -- "true" labels vector of shape (1, number of examples) Returns: cost -- cross-entropy cost given equation (13) """ m = Y.shape[1] # number of examples logprobs = logprobs = np.multiply(Y ,np.log(A2)) + np.multiply((1-Y), np.log(1-A2)) cost = (-1/m) * np.sum(logprobs) cost =float(np.squeeze(cost)) # makes sure cost is the dimension we expect. # E.g., turns [[17]] into 17 return cost
Using the cache computed during forward propagation, you can now implement backward propagation.
Implement the function backward_propagation().
Instructions: Backpropagation is usually the hardest (most mathematical) part in deep learning. To help you, here again is the slide from the lecture on backpropagation. You’ll want to use the six equations on the right of this slide, since you are building a vectorized implementation.
To compute dZ1 you’ll need to compute \(g^{[1]'}(Z^{[1]})\). Since \(g^{[1]}(.)\) is the tanh activation function, if \(a = g^{[1]}(z)\) then \(g^{[1]'}(z) = 1-a^2\). So you can compute \(g^{[1]'}(Z^{[1]})\) using (1 - np.power(A1, 2)).
Code
def backward_propagation(parameters, cache, X, Y):""" Implement the backward propagation using the instructions above. Arguments: parameters -- python dictionary containing our parameters cache -- a dictionary containing "Z1", "A1", "Z2" and "A2". X -- input data of shape (2, number of examples) Y -- "true" labels vector of shape (1, number of examples) Returns: grads -- python dictionary containing your gradients with respect to different parameters """ m = X.shape[1]# First, retrieve W1 and W2 from the dictionary "parameters". W1 = parameters["W1"] b1 = parameters["b1"] W2 = parameters["W2"] b2 = parameters["b2"]# Retrieve also A1 and A2 from dictionary "cache". A1 = cache["A1"] A2 = cache["A2"] Z1 = cache["Z1"] Z2 = cache["Z2"]# Backward propagation: calculate dW1, db1, dW2, db2. dZ2 = A2 - Y dW2 = (1/m) * np.dot(dZ2,A1.T) db2 = (1/m) *(np.sum(dZ2,axis=1,keepdims=True)) dZ1 = np.dot(W2.T,dZ2) * (1- np.power(A1,2)) dW1 = (1/m) *(np.dot(dZ1,X.T)) db1 = (1/m) *(np.sum(dZ1, axis=1, keepdims=True)) grads = {"dW1": dW1,"db1": db1,"dW2": dW2,"db2": db2}return grads
Implement the update rule. Use gradient descent. You have to use (dW1, db1, dW2, db2) in order to update (W1, b1, W2, b2).
General gradient descent rule: \(\theta = \theta - \alpha \frac{\partial J }{ \partial \theta }\) where \(\alpha\) is the learning rate and \(\theta\) represents a parameter.
Hint
Use copy.deepcopy(...) when copying lists or dictionaries that are passed as parameters to functions. It avoids input parameters being modified within the function. In some scenarios, this could be inefficient, but it is required for grading purposes.
Code
def update_parameters(parameters, grads, learning_rate =1.2):""" Updates parameters using the gradient descent update rule given above Arguments: parameters -- python dictionary containing your parameters grads -- python dictionary containing your gradients Returns: parameters -- python dictionary containing your updated parameters """# Retrieve a copy of each parameter from the dictionary "parameters". Use copy.deepcopy(...) for W1 and W2#(≈ 4 lines of code) W1 = parameters["W1"] b1 = parameters["b1"] W2 = parameters["W2"] b2 = parameters["b2"]# Retrieve each gradient from the dictionary "grads" dW1 = grads["dW1"] db1 = grads["db1"] dW2 = grads["dW2"] db2 = grads["db2"]## END CODE HERE #### Update rule for each parameter W1 = W1 - learning_rate * dW1 b1 = b1 - learning_rate * db1 W2 = W2 - learning_rate * dW2 b2 = b2 - learning_rate * db2 parameters = {"W1": W1,"b1": b1,"W2": W2,"b2": b2}return parameters
Instructions: The neural network model has to use the previous functions in the right order.
Code
def nn_model(X, Y, n_h, num_iterations =10000, print_cost=False):""" Arguments: X -- dataset of shape (2, number of examples) Y -- labels of shape (1, number of examples) n_h -- size of the hidden layer num_iterations -- Number of iterations in gradient descent loop print_cost -- if True, print the cost every 1000 iterations Returns: parameters -- parameters learnt by the model. They can then be used to predict. """ np.random.seed(3) n_x = layer_sizes(X, Y)[0] n_y = layer_sizes(X, Y)[2] parameters = initialize_parameters(n_x, n_h, n_y) W1 = parameters["W1"] b1 = parameters["b1"] W2 = parameters["W2"] b2 = parameters["b2"] for i inrange(0, num_iterations):# Forward propagation. Inputs: "X, parameters". Outputs: "A2, cache" A2, cache = forward_propagation(X, parameters)# Cost function. Inputs: "A2, Y, parameters". Outputs: "cost" cost = compute_cost(A2, Y)# Backpropagation. Inputs: "parameters, cache, X, Y". Outputs: "grads" grads = backward_propagation(parameters, cache, X, Y)# Update rule for each parameter parameters = update_parameters(parameters, grads, 1.2)# If print_cost=True, Print the cost every 1000 iterationsif print_cost and i %1000==0:print ("Cost after iteration %i: %f"%(i, cost))# Print the cost every 1000 iterationsif print_cost and i %1000==0:print ("Cost after iteration %i: %f"%(i, cost))return parameters
Code
nn_model_test(nn_model)
Cost after iteration 0: 0.693086
Cost after iteration 0: 0.693086
Cost after iteration 1000: 0.000220
Cost after iteration 1000: 0.000220
Cost after iteration 2000: 0.000108
Cost after iteration 2000: 0.000108
Cost after iteration 3000: 0.000072
Cost after iteration 3000: 0.000072
Cost after iteration 4000: 0.000054
Cost after iteration 4000: 0.000054
Cost after iteration 5000: 0.000043
Cost after iteration 5000: 0.000043
Cost after iteration 6000: 0.000036
Cost after iteration 6000: 0.000036
Cost after iteration 7000: 0.000030
Cost after iteration 7000: 0.000030
Cost after iteration 8000: 0.000027
Cost after iteration 8000: 0.000027
Cost after iteration 9000: 0.000024
Cost after iteration 9000: 0.000024
W1 = [[ 0.71392202 1.31281102]
[-0.76411243 -1.41967065]
[-0.75040545 -1.38857337]
[ 0.56495575 1.04857776]]
b1 = [[-0.0073536 ]
[ 0.01534663]
[ 0.01262938]
[ 0.00218135]]
W2 = [[ 2.82545815 -3.3063945 -3.16116615 1.8549574 ]]
b2 = [[0.00393452]]
All tests passed!
Test the Model
Predict
Predict with your model by building predict(). Use forward propagation to predict results.
As an example, if you would like to set the entries of a matrix X to 0 and 1 based on a threshold you would do: X_new = (X > threshold)
Code
def predict(parameters, X):""" Using the learned parameters, predicts a class for each example in X Arguments: parameters -- python dictionary containing your parameters X -- input data of size (n_x, m) Returns predictions -- vector of predictions of our model (red: 0 / blue: 1) """ A2, cache = forward_propagation(X, parameters) predictions = (A2 >0.5) return predictions
Predictions: [[ True False True]]
All tests passed!
Test the Model on the Planar Dataset
It’s time to run the model and see how it performs on a planar dataset. Run the following code to test your model with a single hidden layer of \(n_h\) hidden units!
Code
# Build a model with a n_h-dimensional hidden layerparameters = nn_model(X, Y, n_h =4, num_iterations =10000, print_cost=True)# Plot the decision boundaryplot_decision_boundary(lambda x: predict(parameters, x.T), X, Y)plt.title("Decision Boundary for hidden layer size "+str(4))
Cost after iteration 0: 0.693162
Cost after iteration 0: 0.693162
Cost after iteration 1000: 0.258625
Cost after iteration 1000: 0.258625
Cost after iteration 2000: 0.239334
Cost after iteration 2000: 0.239334
Cost after iteration 3000: 0.230802
Cost after iteration 3000: 0.230802
Cost after iteration 4000: 0.225528
Cost after iteration 4000: 0.225528
Cost after iteration 5000: 0.221845
Cost after iteration 5000: 0.221845
Cost after iteration 6000: 0.219094
Cost after iteration 6000: 0.219094
Cost after iteration 7000: 0.220661
Cost after iteration 7000: 0.220661
Cost after iteration 8000: 0.219409
Cost after iteration 8000: 0.219409
Cost after iteration 9000: 0.218485
Cost after iteration 9000: 0.218485
Text(0.5, 1.0, 'Decision Boundary for hidden layer size 4')
Accuracy is really high compared to Logistic Regression. The model has learned the patterns of the flower’s petals! Unlike logistic regression, neural networks are able to learn even highly non-linear decision boundaries.
Summary
Here’s a quick recap of this notebook:
Built a complete 2-class classification neural network with a hidden layer
Made good use of a non-linear unit
Computed the cross entropy loss
Implemented forward and backward propagation
Seen the impact of varying the hidden layer size, including overfitting.
We have designed a neural network that can learn patterns! Some optional exercises to try out some other hidden layer sizes, and other datasets.
Tuning hidden layer size
Run the following code(it may take 1-2 minutes). Then, observe different behaviors of the model for various hidden layer sizes.
Code
# This may take about 2 minutes to runplt.figure(figsize=(16, 32))hidden_layer_sizes = [1, 2, 3, 4, 5]# you can try with different hidden layer sizes# but make sure before you submit the assignment it is set as "hidden_layer_sizes = [1, 2, 3, 4, 5]"# hidden_layer_sizes = [1, 2, 3, 4, 5, 20, 50]for i, n_h inenumerate(hidden_layer_sizes): plt.subplot(5, 2, i+1) plt.title('Hidden Layer of size %d'% n_h) parameters = nn_model(X, Y, n_h, num_iterations =5000) plot_decision_boundary(lambda x: predict(parameters, x.T), X, Y) predictions = predict(parameters, X) accuracy =float((np.dot(Y,predictions.T) + np.dot(1- Y, 1- predictions.T)) /float(Y.size)*100)print ("Accuracy for {} hidden units: {} %".format(n_h, accuracy))
Interpretation: - The larger models (with more hidden units) are able to fit the training set better, until eventually the largest models overfit the data. - The best hidden layer size seems to be around n_h = 5. Indeed, a value around here seems to fits the data well without also incurring noticeable overfitting. - Later, you’ll become familiar with regularization, which lets you use very large models (such as n_h = 50) without much overfitting.
Note: Remember to submit the assignment by clicking the blue “Submit Assignment” button at the upper-right.
Some experiments: - What happens when you change the tanh activation for a sigmoid activation or a ReLU activation? - Play with the learning_rate. What happens? - What if we change the dataset? (See part 7 below!)
Performance on other datasets
If you want, you can rerun the whole notebook (minus the dataset part) for each of the following datasets.
Code
# Datasetsnoisy_circles, noisy_moons, blobs, gaussian_quantiles, no_structure = load_extra_datasets()datasets = {"noisy_circles": noisy_circles,"noisy_moons": noisy_moons,"blobs": blobs,"gaussian_quantiles": gaussian_quantiles}dataset ="noisy_moons"X, Y = datasets[dataset]X, Y = X.T, Y.reshape(1, Y.shape[0])# make blobs binaryif dataset =="blobs": Y = Y%2# Visualize the dataplt.scatter(X[0, :], X[1, :], c=Y, s=40, cmap=plt.cm.Spectral);