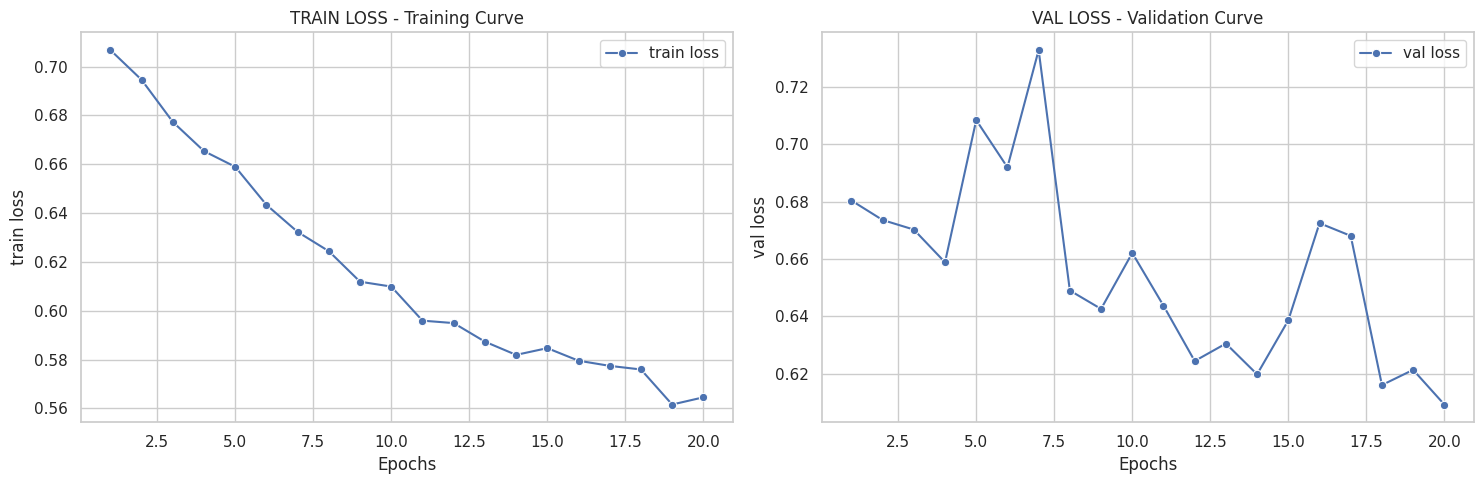
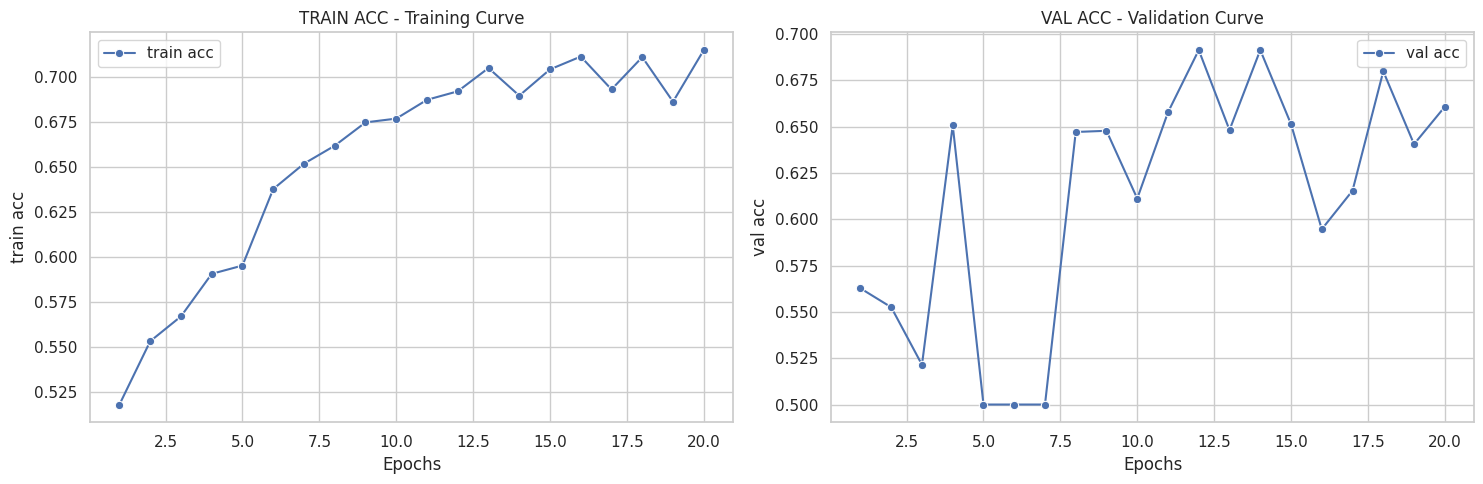
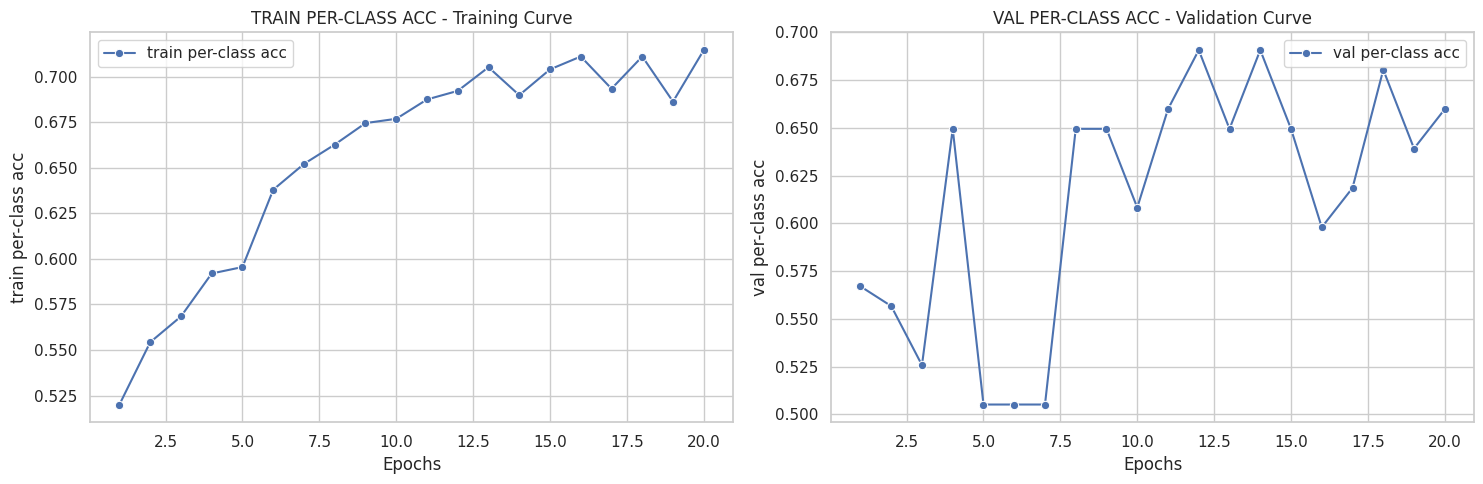
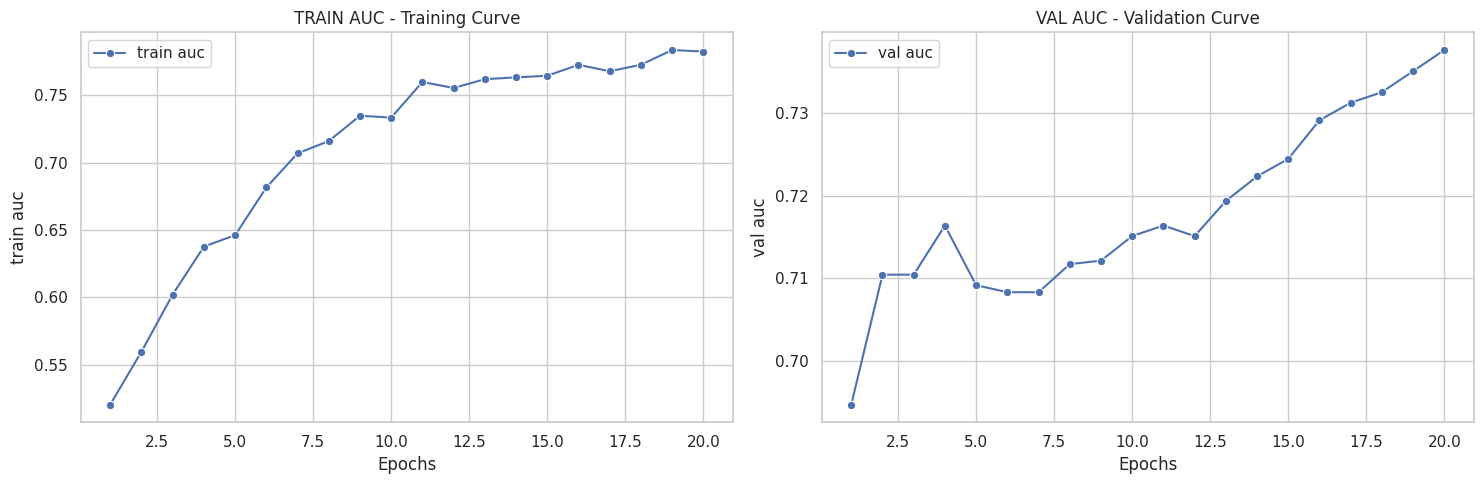
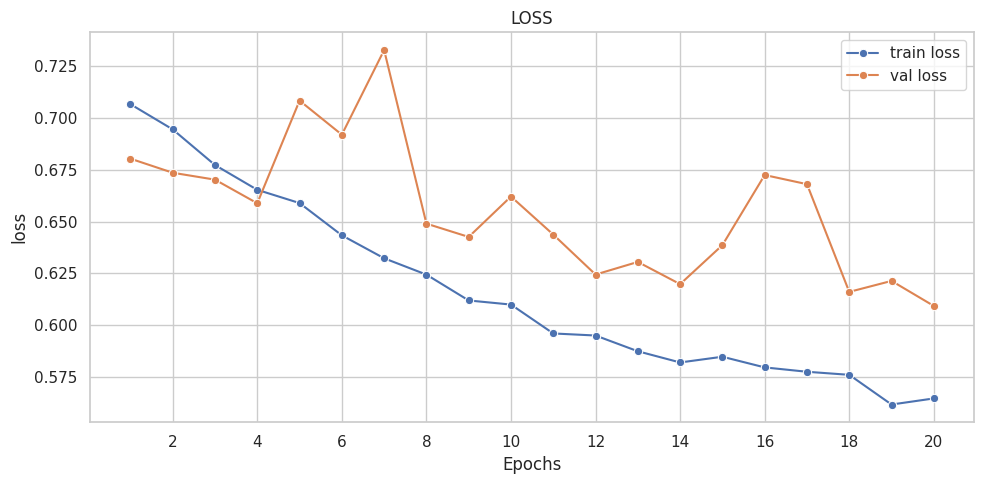
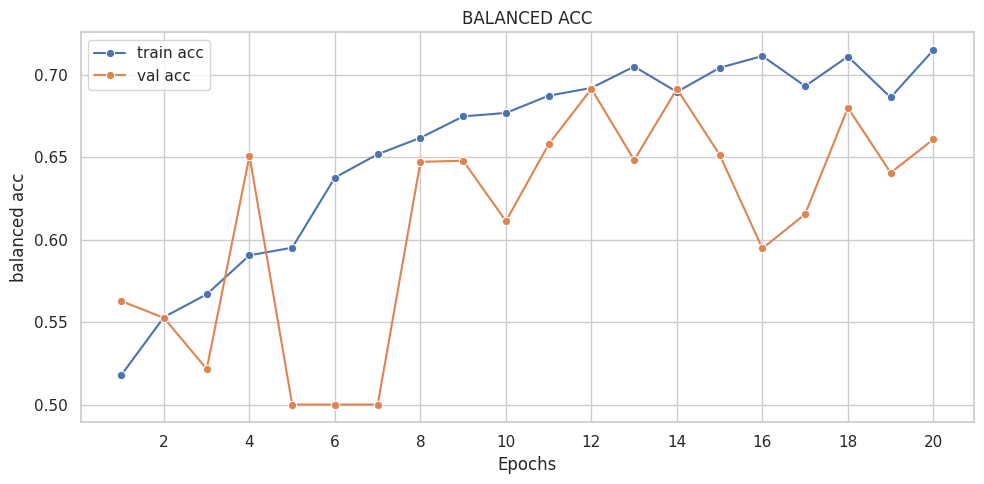
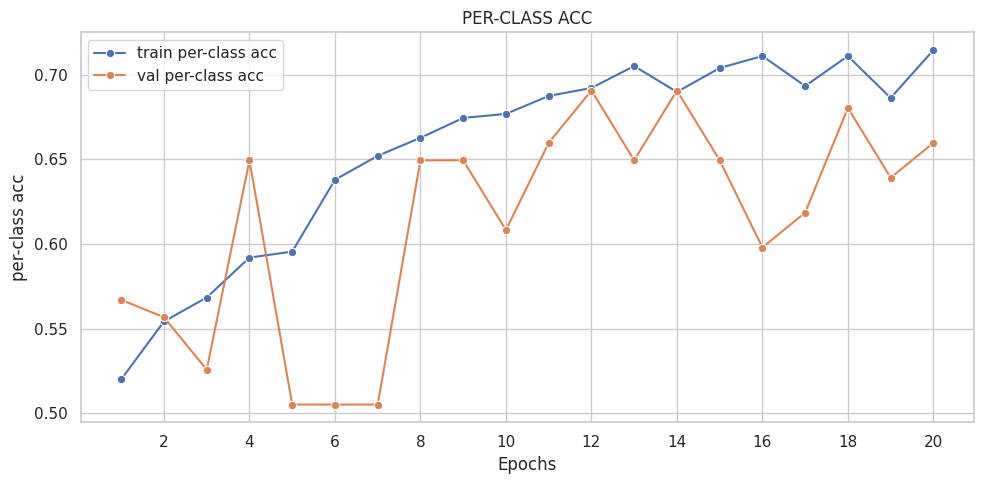
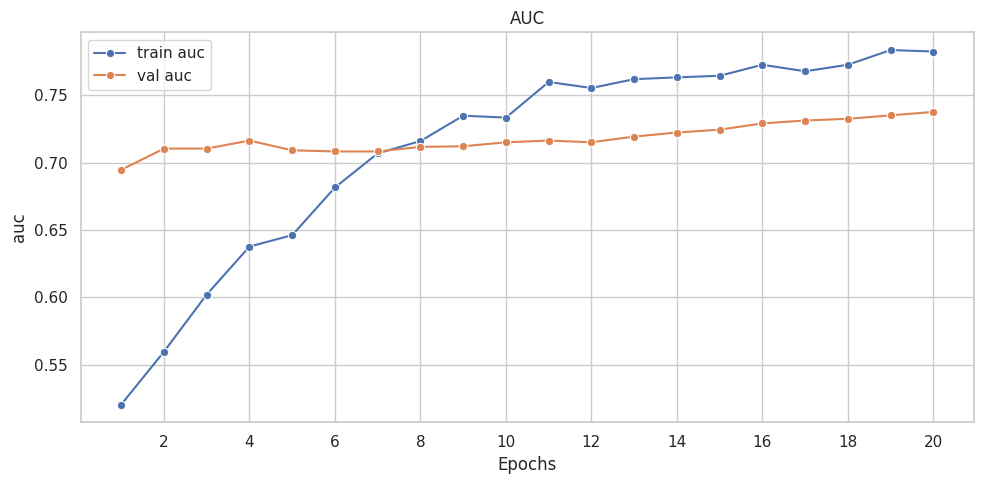
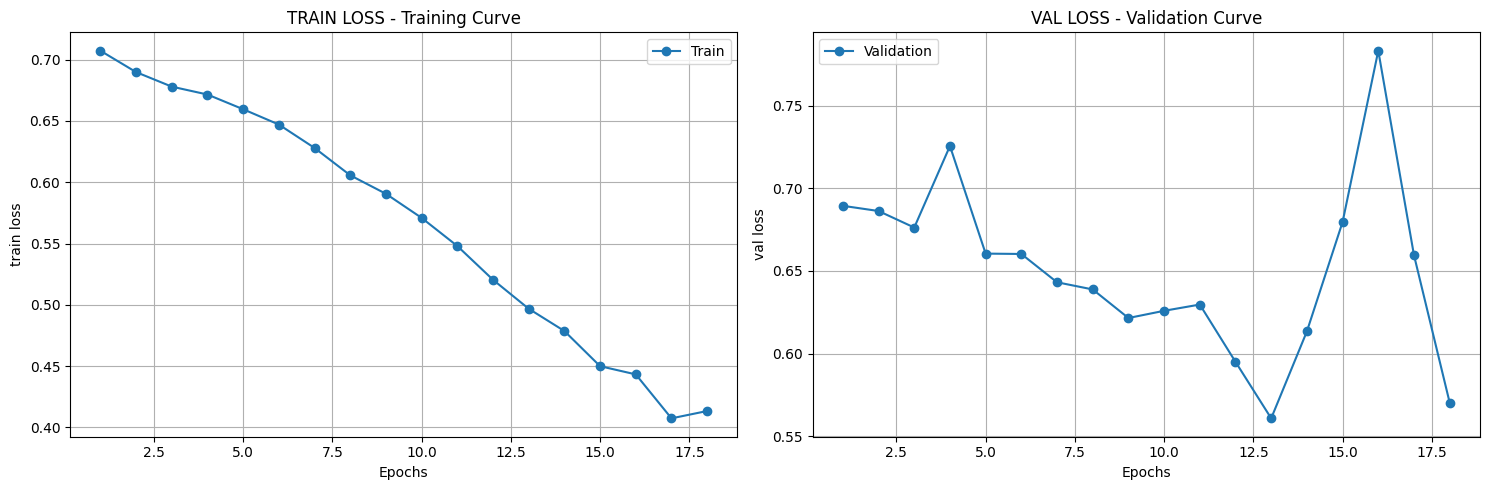
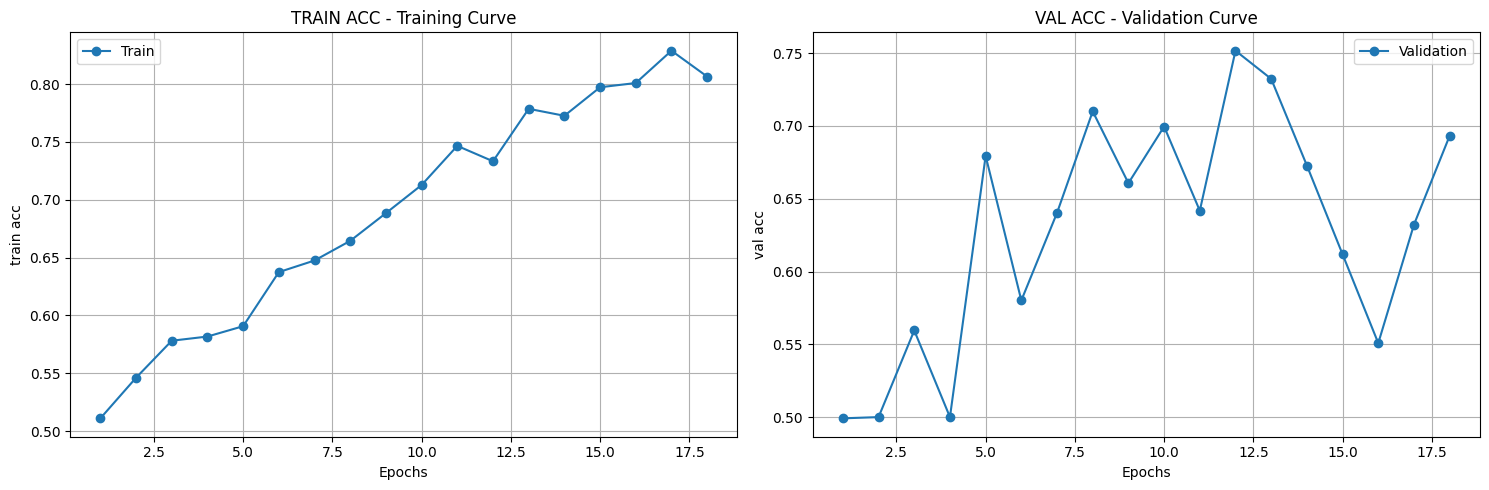
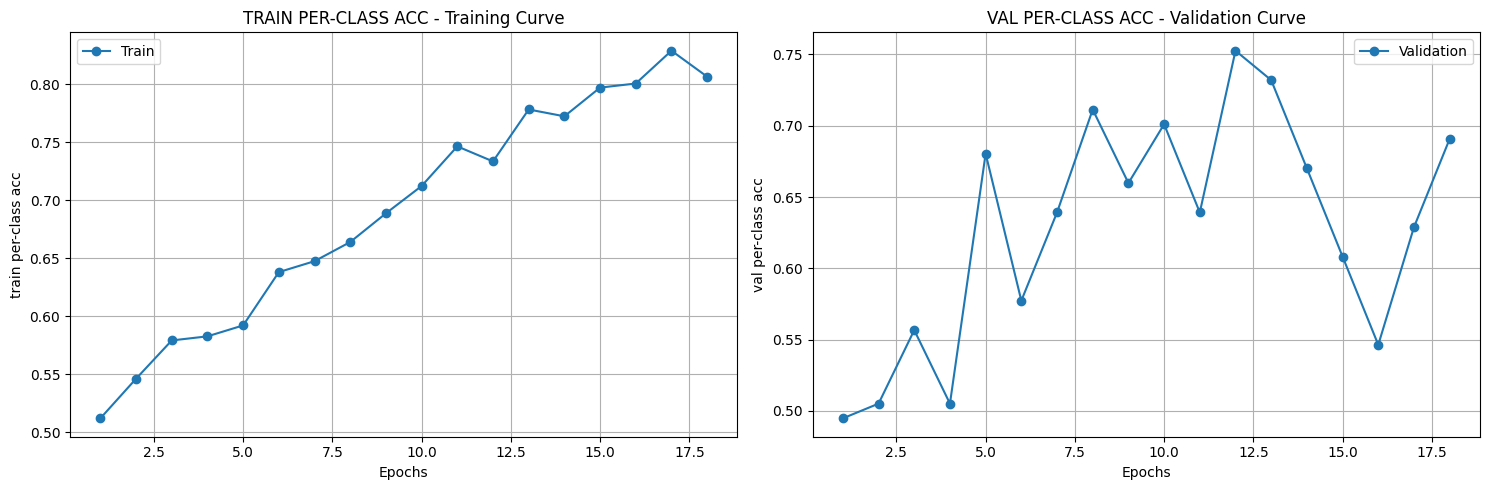
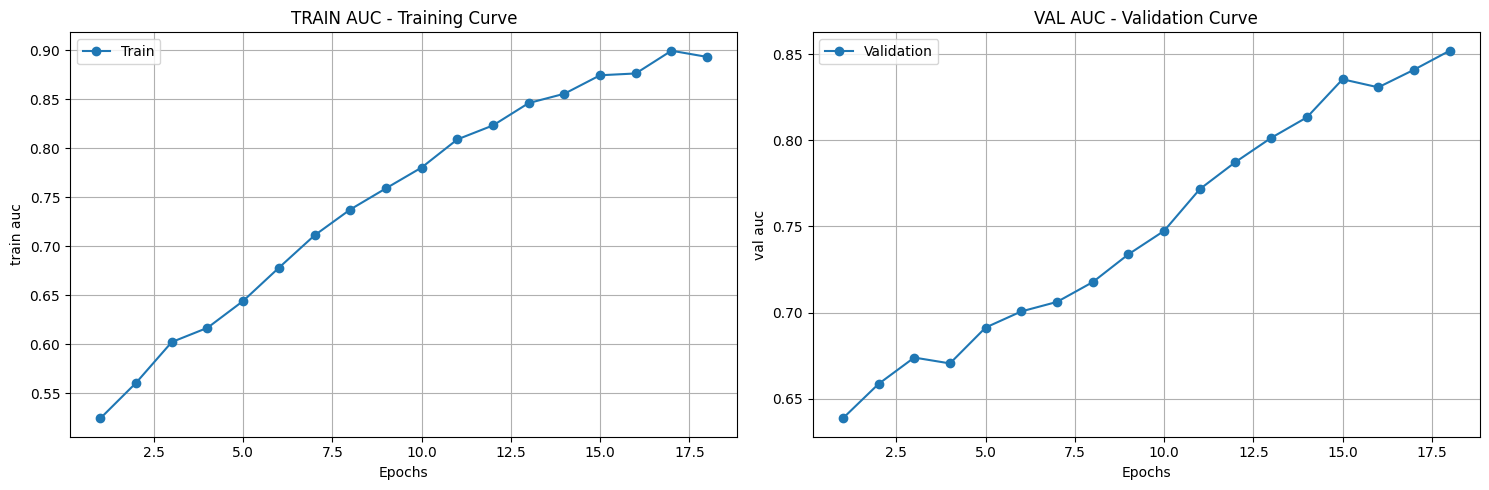
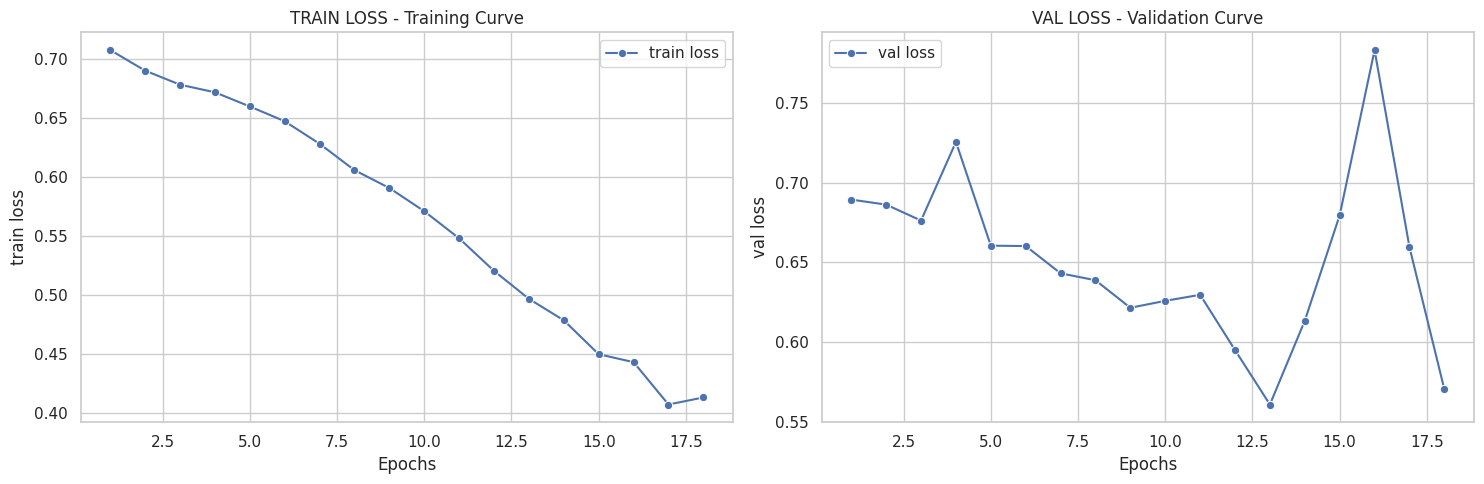
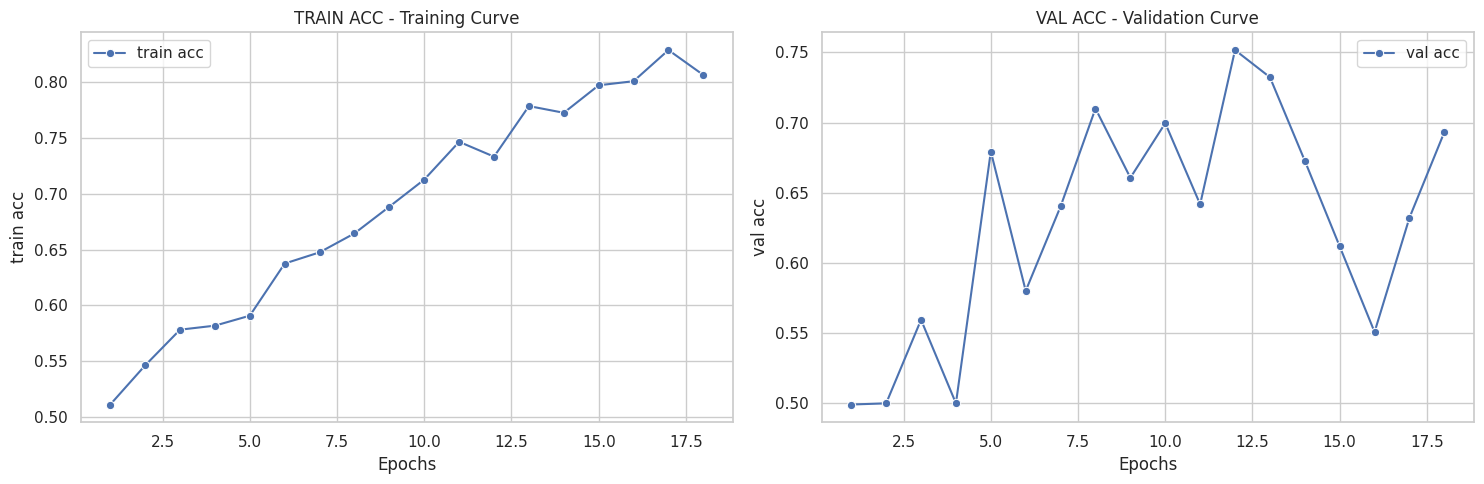
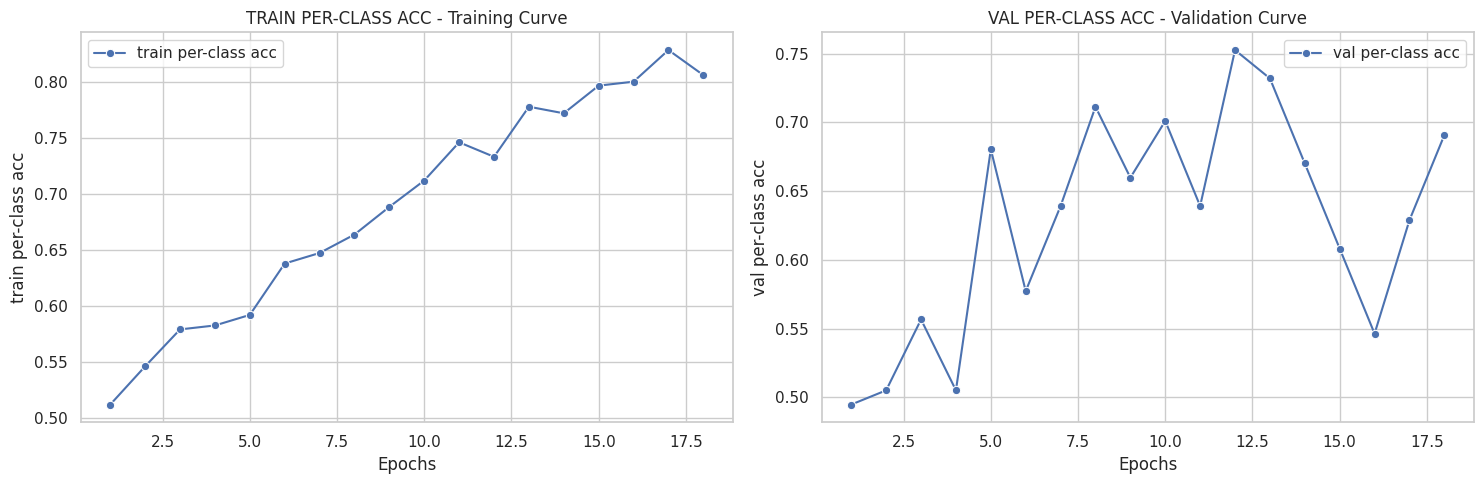
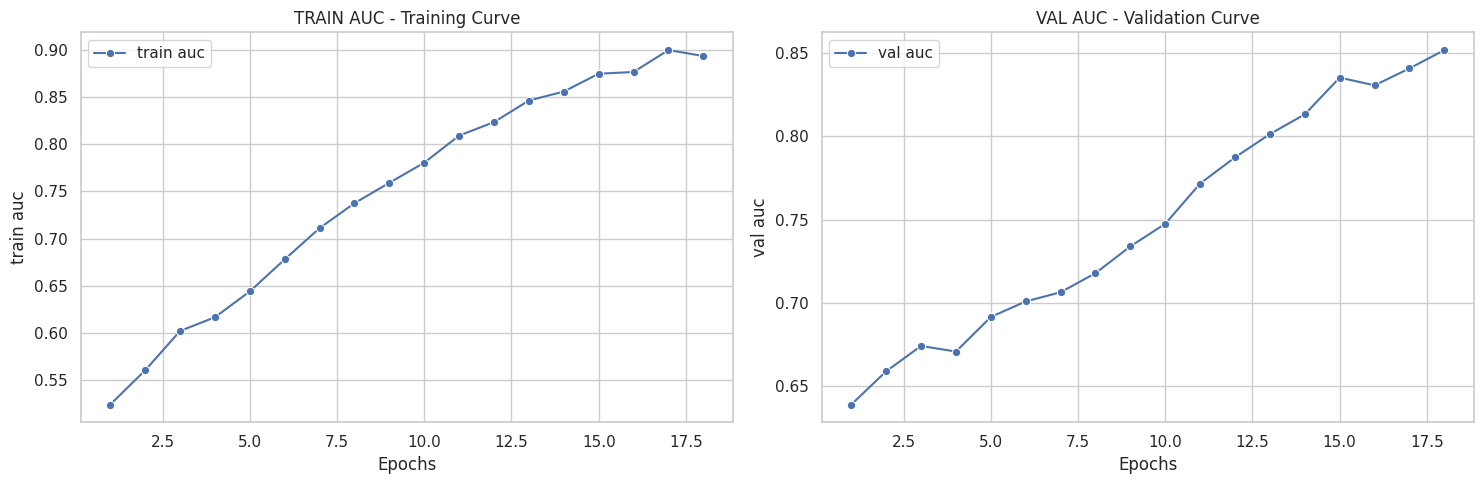
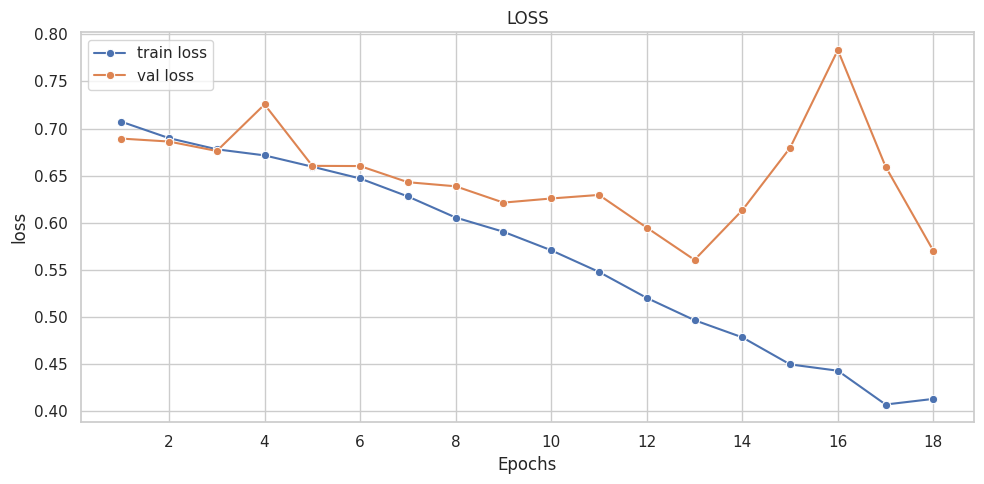
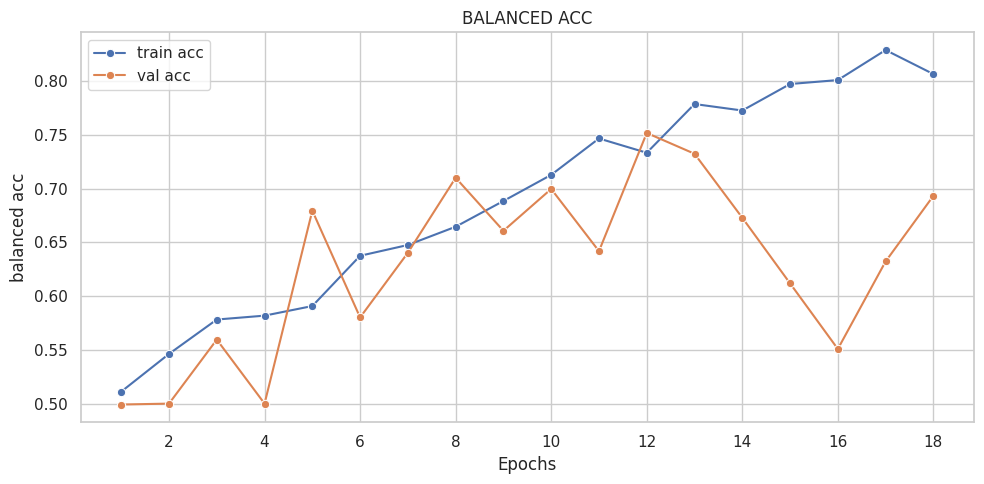
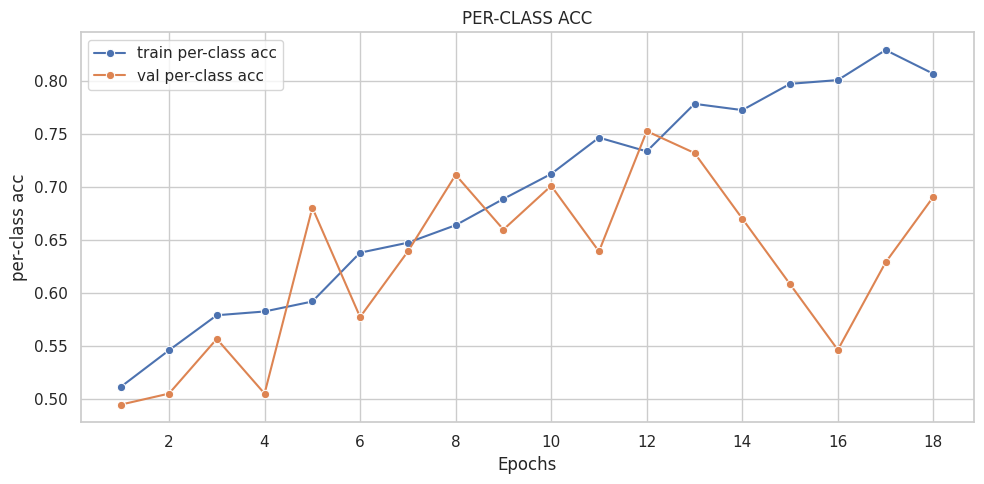
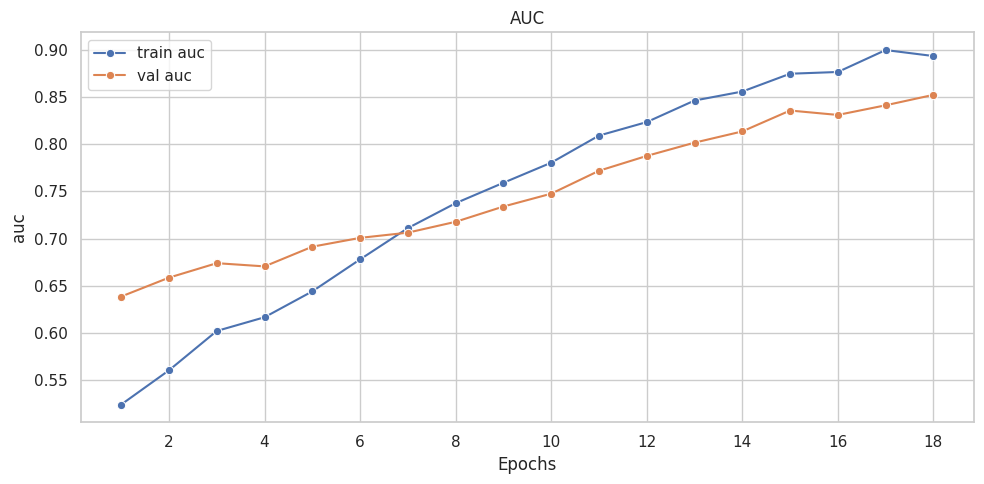
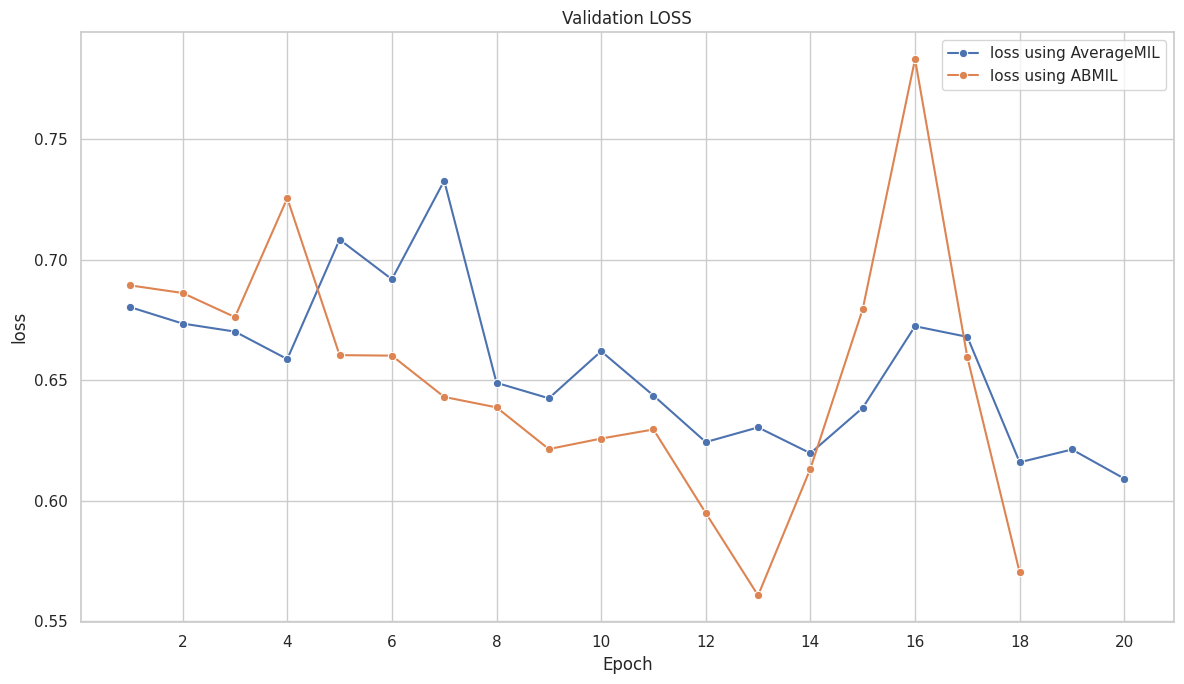
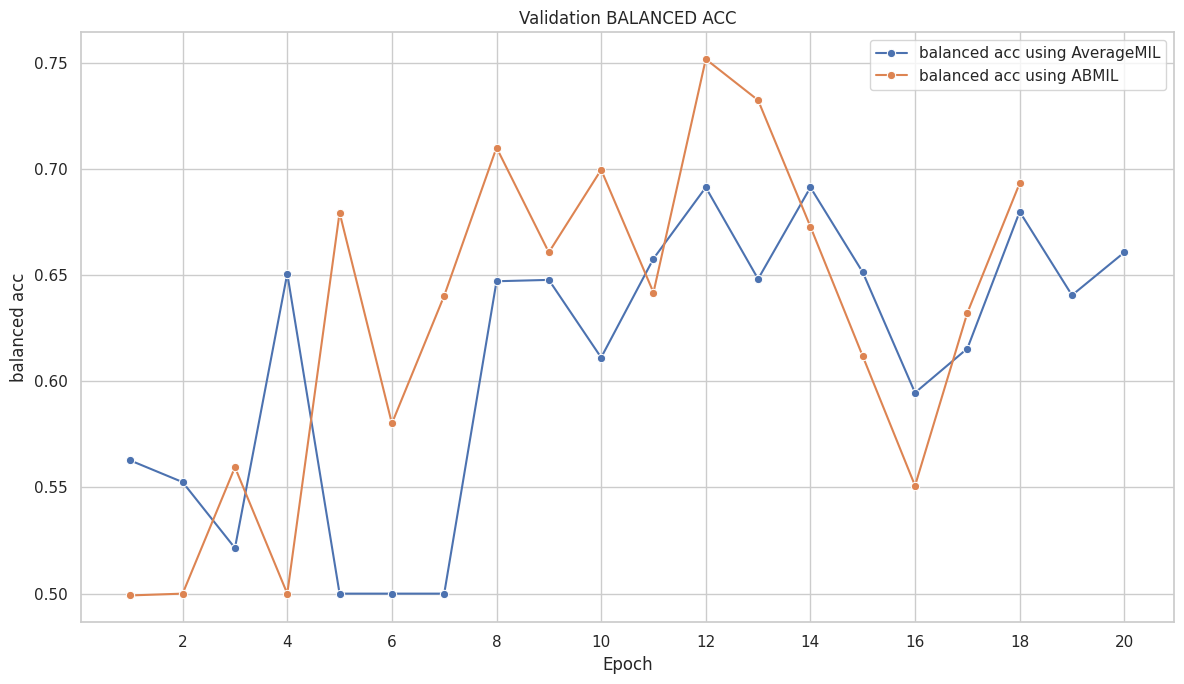
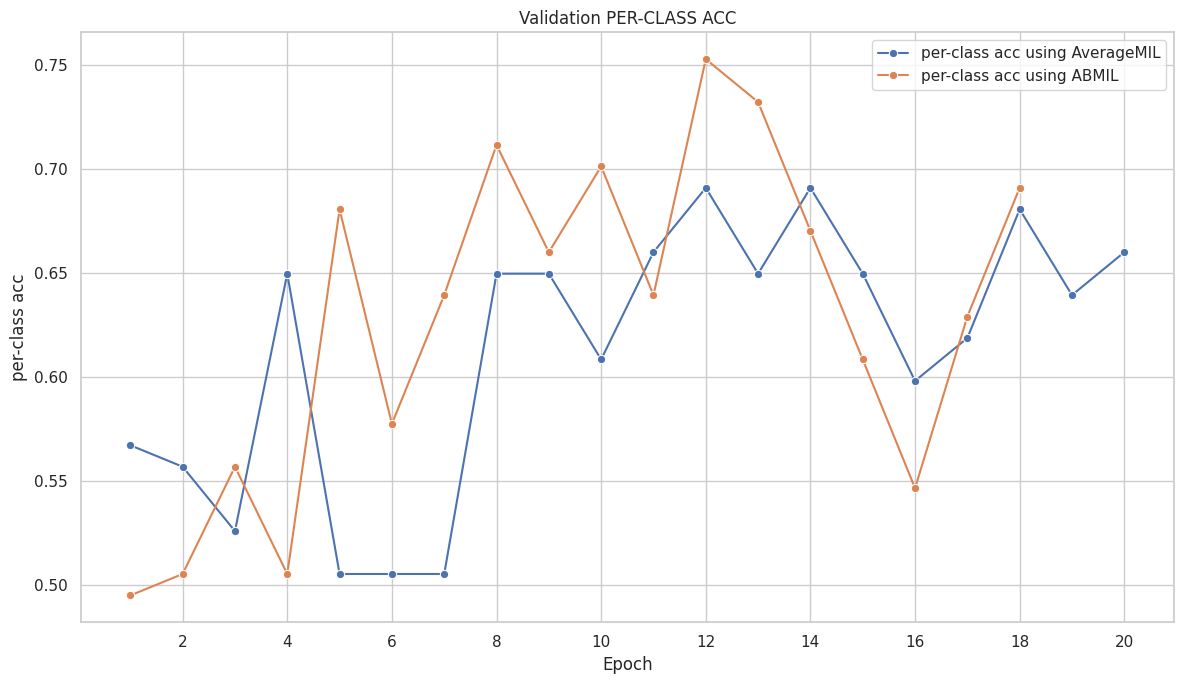
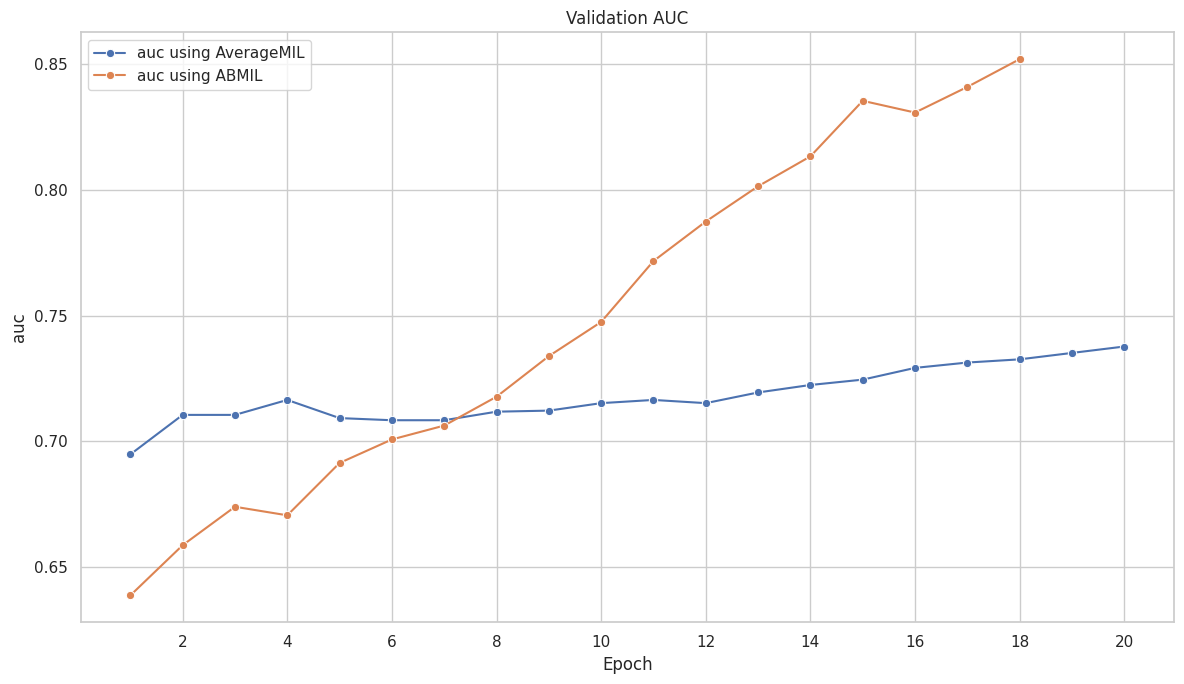
([{'val loss': 0.6803982134946843,
'val acc': 0.5627125850340136,
'val per-class acc': 0.5670103092783505,
'val auc': 0.6947278911564626},
{'val loss': 0.6735972857352385,
'val acc': 0.5525085034013605,
'val per-class acc': 0.5567010309278351,
'val auc': 0.7104591836734694},
{'val loss': 0.6702608410845098,
'val acc': 0.5214710884353742,
'val per-class acc': 0.5257731958762887,
'val auc': 0.7104591836734694},
{'val loss': 0.658846736876006,
'val acc': 0.6507227891156463,
'val per-class acc': 0.6494845360824743,
'val auc': 0.7164115646258503},
{'val loss': 0.7084451502131432,
'val acc': 0.5,
'val per-class acc': 0.5051546391752577,
'val auc': 0.7091836734693877},
{'val loss': 0.6919781800705133,
'val acc': 0.5,
'val per-class acc': 0.5051546391752577,
'val auc': 0.7083333333333335},
{'val loss': 0.7328733577556217,
'val acc': 0.5,
'val per-class acc': 0.5051546391752577,
'val auc': 0.7083333333333334},
{'val loss': 0.6490099599066469,
'val acc': 0.6471088435374149,
'val per-class acc': 0.6494845360824743,
'val auc': 0.7117346938775511},
{'val loss': 0.6425867612214432,
'val acc': 0.6477465986394558,
'val per-class acc': 0.6494845360824743,
'val auc': 0.7121598639455783},
{'val loss': 0.6621069063230888,
'val acc': 0.6111819727891157,
'val per-class acc': 0.6082474226804123,
'val auc': 0.7151360544217689},
{'val loss': 0.6437243203219679,
'val acc': 0.6577380952380952,
'val per-class acc': 0.6597938144329897,
'val auc': 0.7164115646258504},
{'val loss': 0.6244144886732101,
'val acc': 0.6913265306122449,
'val per-class acc': 0.6907216494845361,
'val auc': 0.7151360544217686},
{'val loss': 0.6305080309663851,
'val acc': 0.648171768707483,
'val per-class acc': 0.6494845360824743,
'val auc': 0.7193877551020408},
{'val loss': 0.6197766895146714,
'val acc': 0.6913265306122449,
'val per-class acc': 0.6907216494845361,
'val auc': 0.7223639455782312},
{'val loss': 0.6386314140459926,
'val acc': 0.6513605442176871,
'val per-class acc': 0.6494845360824743,
'val auc': 0.7244897959183674},
{'val loss': 0.6724980127104779,
'val acc': 0.5946003401360545,
'val per-class acc': 0.5979381443298969,
'val auc': 0.7291666666666667},
{'val loss': 0.668074183780508,
'val acc': 0.6154336734693877,
'val per-class acc': 0.6185567010309279,
'val auc': 0.7312925170068028},
{'val loss': 0.6160321704198405,
'val acc': 0.6798469387755102,
'val per-class acc': 0.6804123711340206,
'val auc': 0.7325680272108844},
{'val loss': 0.6213401637433731,
'val acc': 0.6405187074829932,
'val per-class acc': 0.6391752577319587,
'val auc': 0.7351190476190477},
{'val loss': 0.6092413214524997,
'val acc': 0.6607142857142857,
'val per-class acc': 0.6597938144329897,
'val auc': 0.7376700680272109}],
[{'train loss': 0.7067322431413351,
'train acc': 0.5178023873786137,
'train per-class acc': 0.5200471698113207,
'train auc': 0.5205153176215254},
{'train loss': 0.6945402914623044,
'train acc': 0.5529925707448733,
'train per-class acc': 0.5542452830188679,
'train auc': 0.5597651576282033},
{'train loss': 0.677320071724507,
'train acc': 0.5667992988118757,
'train per-class acc': 0.5683962264150944,
'train auc': 0.6021647792092156},
{'train loss': 0.6653487175211029,
'train acc': 0.5904449205598374,
'train per-class acc': 0.5919811320754716,
'train auc': 0.6377472940259885},
{'train loss': 0.6589468236626038,
'train acc': 0.5950610757116225,
'train per-class acc': 0.5955188679245284,
'train auc': 0.6462172013689863},
{'train loss': 0.6433602210555999,
'train acc': 0.6375831269651353,
'train per-class acc': 0.6379716981132075,
'train auc': 0.6815938117365536},
{'train loss': 0.6322723758529942,
'train acc': 0.6516903642282756,
'train per-class acc': 0.652122641509434,
'train auc': 0.7069144940037286},
{'train loss': 0.6243803047065465,
'train acc': 0.6616822949998609,
'train per-class acc': 0.6627358490566038,
'train auc': 0.7160410695901389},
{'train loss': 0.6118933894794505,
'train acc': 0.6746320153593589,
'train per-class acc': 0.6745283018867925,
'train auc': 0.7348618492445533},
{'train loss': 0.6099064529627422,
'train acc': 0.6767411447174378,
'train per-class acc': 0.6768867924528302,
'train auc': 0.7334372130554551},
{'train loss': 0.5959538500316722,
'train acc': 0.6871838392832299,
'train per-class acc': 0.6875,
'train auc': 0.7598875873007038},
{'train loss': 0.594957460710814,
'train acc': 0.6919029466596177,
'train per-class acc': 0.6922169811320755,
'train auc': 0.7554189042544311},
{'train loss': 0.5873530111627056,
'train acc': 0.7048554495116726,
'train per-class acc': 0.7051886792452831,
'train auc': 0.7619855866885555},
{'train loss': 0.5819371846276071,
'train acc': 0.6894933081054009,
'train per-class acc': 0.6898584905660378,
'train auc': 0.7633044881604942},
{'train loss': 0.5847031294702077,
'train acc': 0.704101394028771,
'train per-class acc': 0.7040094339622641,
'train auc': 0.7645176549152731},
{'train loss': 0.5795527598732766,
'train acc': 0.7112301399593756,
'train per-class acc': 0.7110849056603774,
'train auc': 0.772653663151451},
{'train loss': 0.5774440601872245,
'train acc': 0.6929575113386572,
'train per-class acc': 0.6933962264150944,
'train auc': 0.7678343860430173},
{'train loss': 0.575963072298657,
'train acc': 0.7109296307632377,
'train per-class acc': 0.7110849056603774,
'train auc': 0.772687053062133},
{'train loss': 0.5616160210019926,
'train acc': 0.6861292746041905,
'train per-class acc': 0.6863207547169812,
'train auc': 0.7835832939146888},
{'train loss': 0.5645616454520386,
'train acc': 0.7148445977907009,
'train per-class acc': 0.714622641509434,
'train auc': 0.7825036868026378}])